注:本文的内容大部分转载自 聊聊MyBatis缓存机制 - 美团技术团队 和 Mybatis详解 - Java全栈知识体系
这篇文章记录我在学习 Mybaits 源码的一些记录,包含两部分,这是第二部分,主要是来学习一下 Mybatis 中的缓存机制。
先从一张图看一下一级缓存和二级缓存的工作模式:
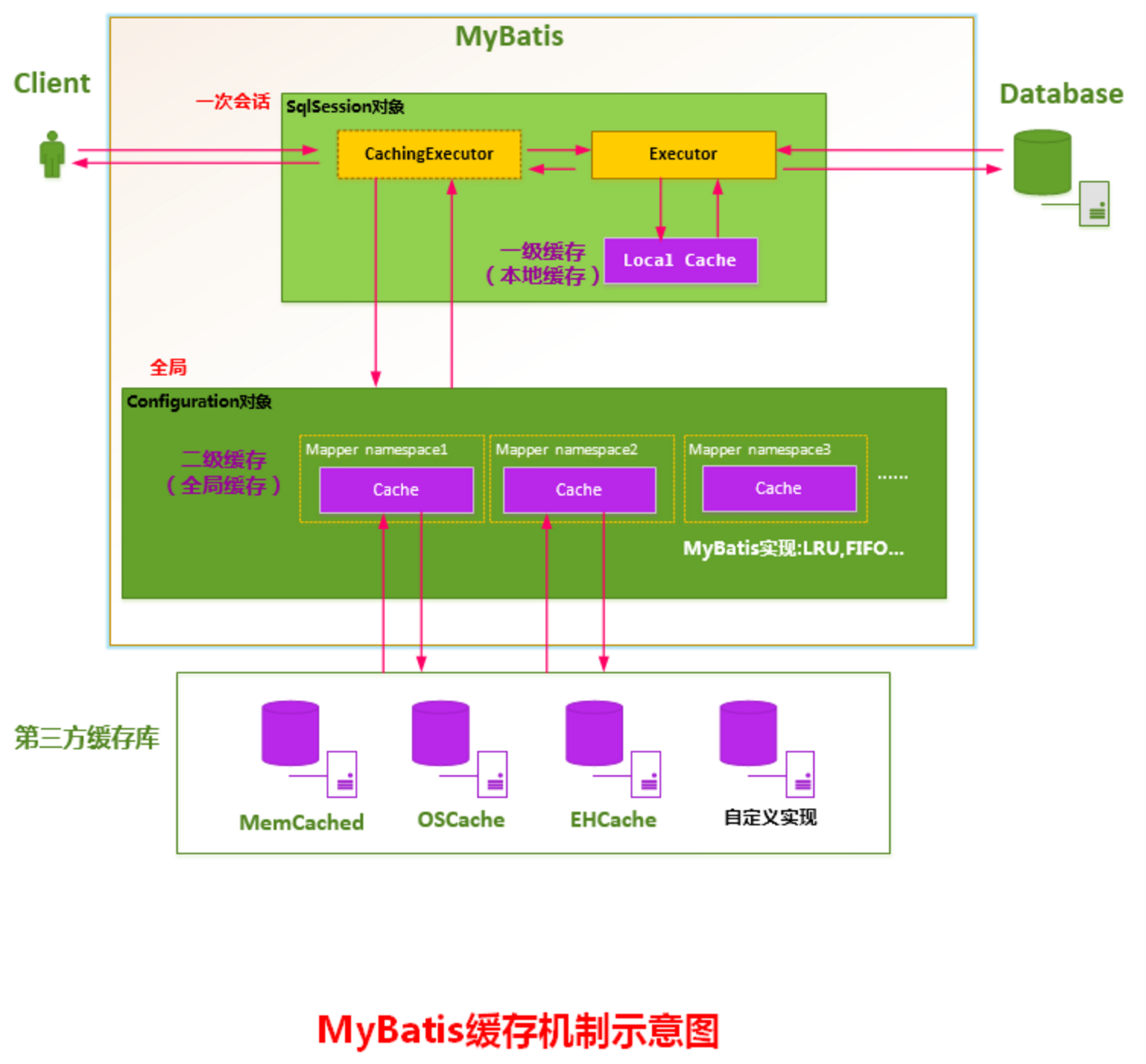
详细内容见 聊聊MyBatis缓存机制 - 美团技术团队,这里只选取其中部分内容:
一级缓存(本地缓存)
Mybatis 中的一级缓存执行过程,一级缓存是在执行多次查询条件完全相同的 sql 语句时命中的缓存,可以避免直接对数据库进行查询。
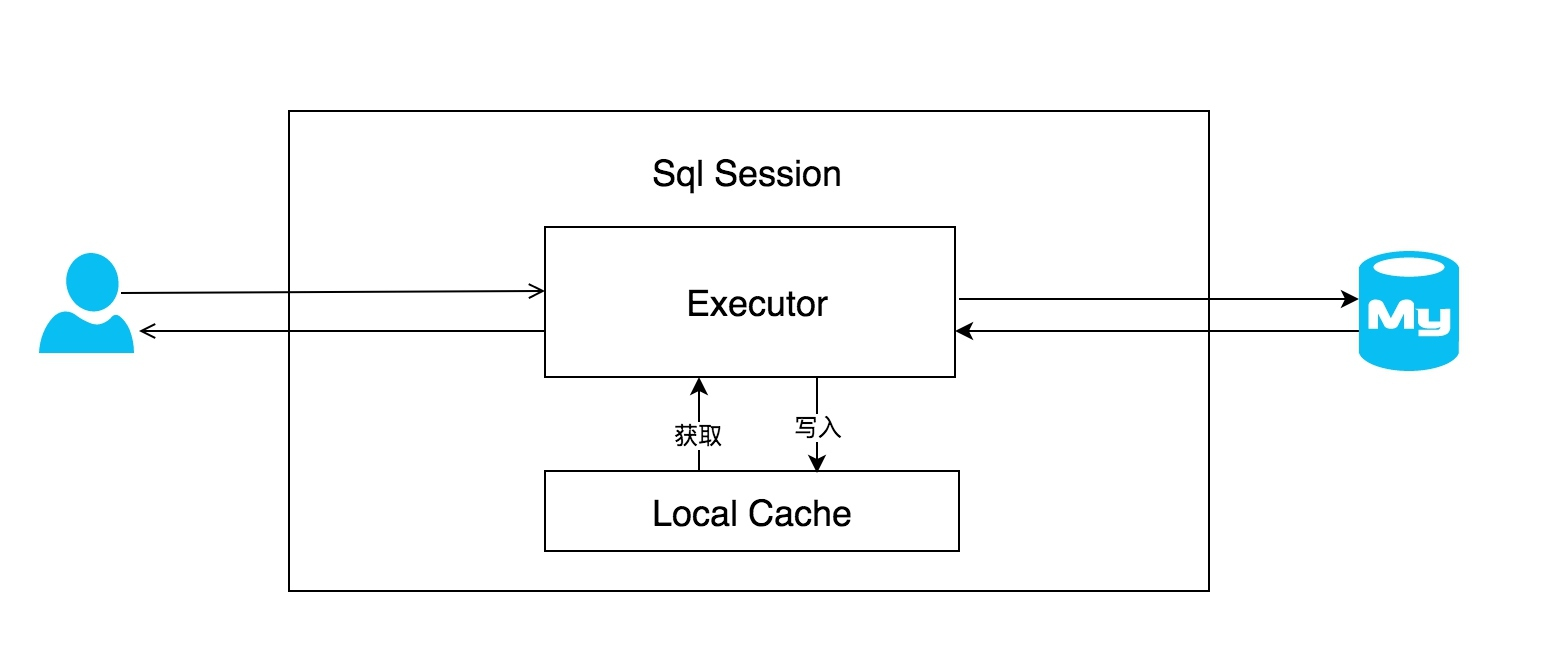
重复查询命中一级缓存案例

一级缓存执行时序图如下,从时序图可以看出,SqlSession 是向用户提供操作数据库方法的入口,真正与数据库进行交互的则是 Executor。
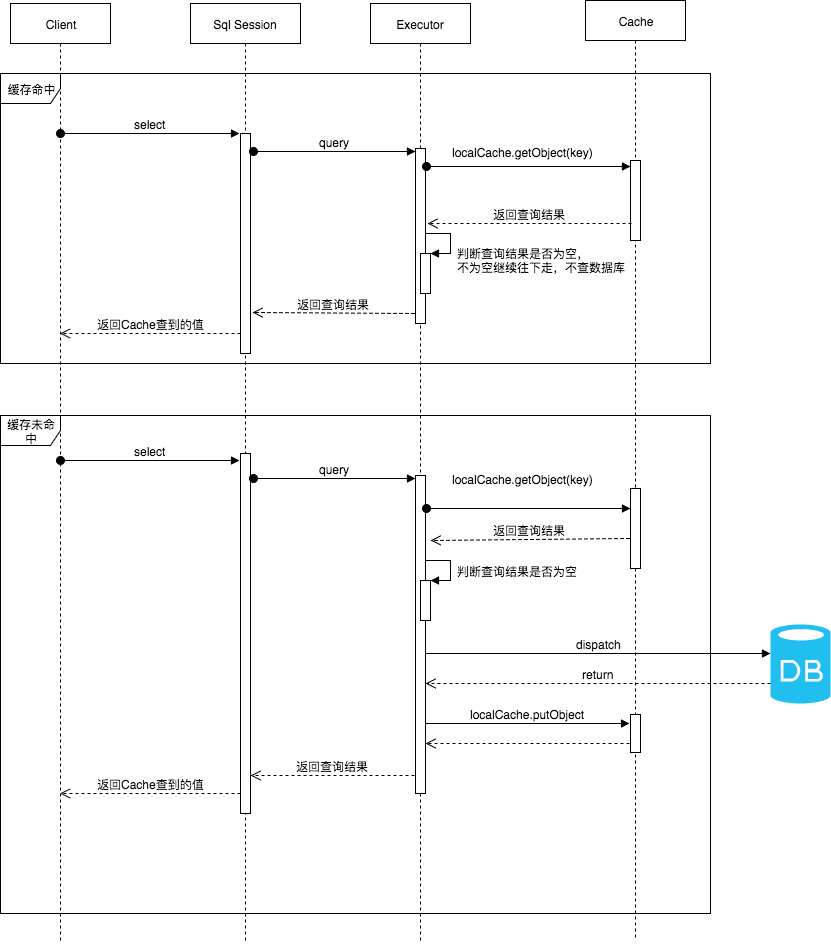
接着看下 SqlSession 是如何初始化的,首先看下 Mybatis 的配置文件,这里的配置大概有个印象,在后续进行源码分析时都会讲到:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| <configuration>
<properties resource="local-mysql.properties"/>
<settings>
<setting name="localCacheScope" value="SESSION"/>
<setting name="cacheEnabled" value="true"/>
<setting name="mapUnderscoreToCamelCase" value="true"/>
<setting name="logImpl" value="LOG4J"/>
</settings>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="mapper/studentMapper.xml"/>
<mapper resource="mapper/classMapper.xml"/>
</mappers>
</configuration>
|
为执行和数据库的交互,首先需要初始化 SqlSession,通过 DefaultSqlSessionFactory 开启 SqlSession:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| @Override
public SqlSession openSession() {
return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false);
}
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
final Environment environment = configuration.getEnvironment();
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
final Executor executor = configuration.newExecutor(tx, execType);
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx);
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
|
Executor 创建过程如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
|
下面通过 SqlSession 的 selectList() 方法,来看一下 SqlSession 和 Executor 的执行过程,从 DefaultSqlSession 中开始看:
1
2
3
4
5
6
7
8
9
10
11
| private <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.query(ms, wrapCollection(parameter), rowBounds, handler);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
|
Executor 的 query() 方法
1
2
3
4
5
6
7
8
| @Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameter);
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
|
注意其中的 CacheKey,这个 CacheKey 就是 Mybatis 的保存一级缓存时的 key,Mybatis 根据这个 key 来判断 sql 语句是否在一级缓存中存在,它重写了 equals() 方法。对于两次查询,如果下面的条件完全一样,那么认为它们是完全相同的两次查询:
- 传入的
statementId
- 查询时要求的结果集中的结果范围 (结果的范围通过
rowBounds.offset 和 rowBounds.limit 表示)。注:mybatis 的分页功能是通过 rowBounds 实现的。
- 这次查询所产生的最终要传递给
JDBC java.sql.Preparedstatement 的 Sql 语句字符串(boundSql.getSql())
- 传递给
java.sql.Statement 要设置的参数值。与第三点要求联合使用:调用JDBC的时候,传入的SQL语句要完全相同,传递给JDBC的参数值也要完全相同。
看下 BaseExecutor.class 中创建 CacheKey 相关的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
| @Override
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if (closed) {
throw new ExecutorException("Executor was closed.");
}
CacheKey cacheKey = new CacheKey();
cacheKey.update(ms.getId());
cacheKey.update(rowBounds.getOffset());
cacheKey.update(rowBounds.getLimit());
cacheKey.update(boundSql.getSql());
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
for (ParameterMapping parameterMapping : parameterMappings) {
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
cacheKey.update(value);
}
}
if (configuration.getEnvironment() != null) {
cacheKey.update(configuration.getEnvironment().getId());
}
return cacheKey;
}
public void update(Object object) {
int baseHashCode = object == null ? 1 : ArrayUtil.hashCode(object);
count++;
checksum += baseHashCode;
baseHashCode *= count;
hashcode = multiplier * hashcode + baseHashCode;
updateList.add(object);
}
@Override
public boolean equals(Object object) {
if (this == object) {
return true;
}
if (!(object instanceof CacheKey)) {
return false;
}
final CacheKey cacheKey = (CacheKey) object;
if (hashcode != cacheKey.hashcode) {
return false;
}
if (checksum != cacheKey.checksum) {
return false;
}
if (count != cacheKey.count) {
return false;
}
for (int i = 0; i < updateList.size(); i++) {
Object thisObject = updateList.get(i);
Object thatObject = cacheKey.updateList.get(i);
if (!ArrayUtil.equals(thisObject, thatObject)) {
return false;
}
}
return true;
}
|
继续看 query 方法,注意最后,如果一级缓存的作用范围是 Statement,那么在一次查询结束后,就会清空一级缓存,也就是说一级缓存会失效:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| @Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
clearLocalCache();
}
}
return list;
}
|
一级缓存只有在执行查询方法才会命中,在执行 update/insert 方法时不会命中,看一下代码:
1
2
3
4
5
6
7
8
| @Override
public int insert(String statement, Object parameter) {
return update(statement, parameter);
}
@Override
public int delete(String statement) {
return update(statement, null);
}
|
看下代码,每次执行时,都会执行 clearLocalCache() 清空一级缓存:
1
2
3
4
5
6
7
8
9
10
| @Override
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
clearLocalCache();
return doUpdate(ms, parameter);
}
|
下面来总结下关于一级缓存的几个关键点:
- 一级缓存使用
HashMap 维护,是一个粗粒度的缓存,没有更新缓存和缓存过期的概念。
- 每个
SqlSession 创建时都会持有单独的一级缓存,SqlSession 消亡后一级缓存也会被清空,执行 updat/insert/delete 操作也会清空一级缓存。
二级缓存(全局缓存)
Mybatis 的二级缓存有两种配置模式:
每个 Mapper 单独享有一个 Cache 缓存对象。
MyBatis 将 Application 级别的二级缓存细分到 Mapper 级别,即对于每一个 Mapper.xml ,如果在其中使用了<cache/> 节点,则 MyBatis 会为这个 Mapper 创建一个 Cache 缓存对象,如下图:
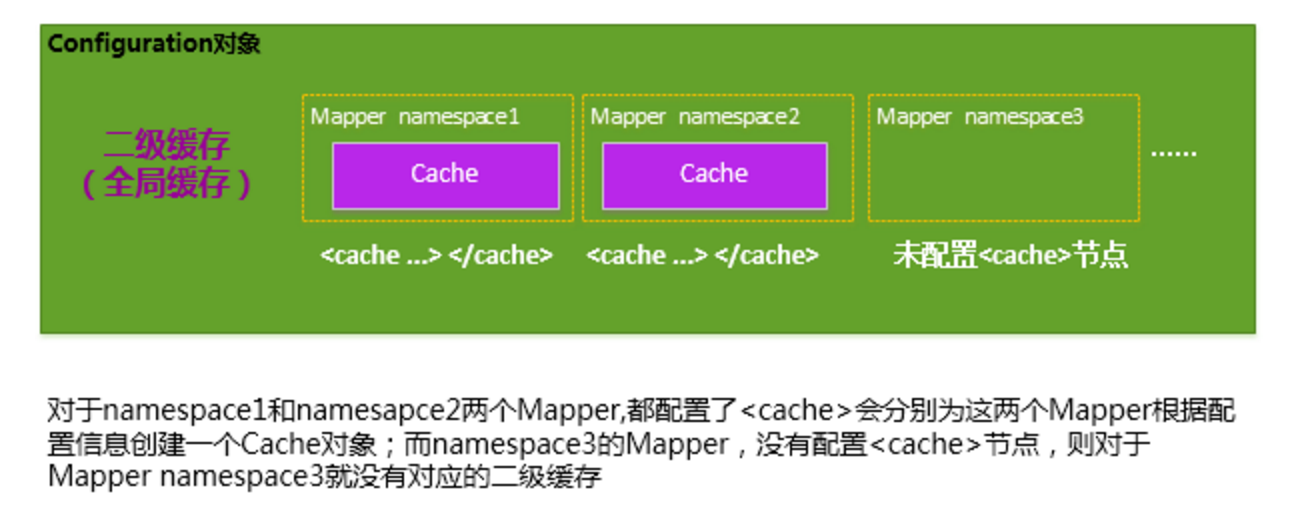
多个 Mapper 共用一个 Cache 缓存对象。
如果你想让多个 Mapper 公用一个 Cache 的话,你可以使用 <cache-ref namespace=""> 节点,来指定你的这个 Mapper 使用到了哪一个 Mapper 的 Cache 缓存。
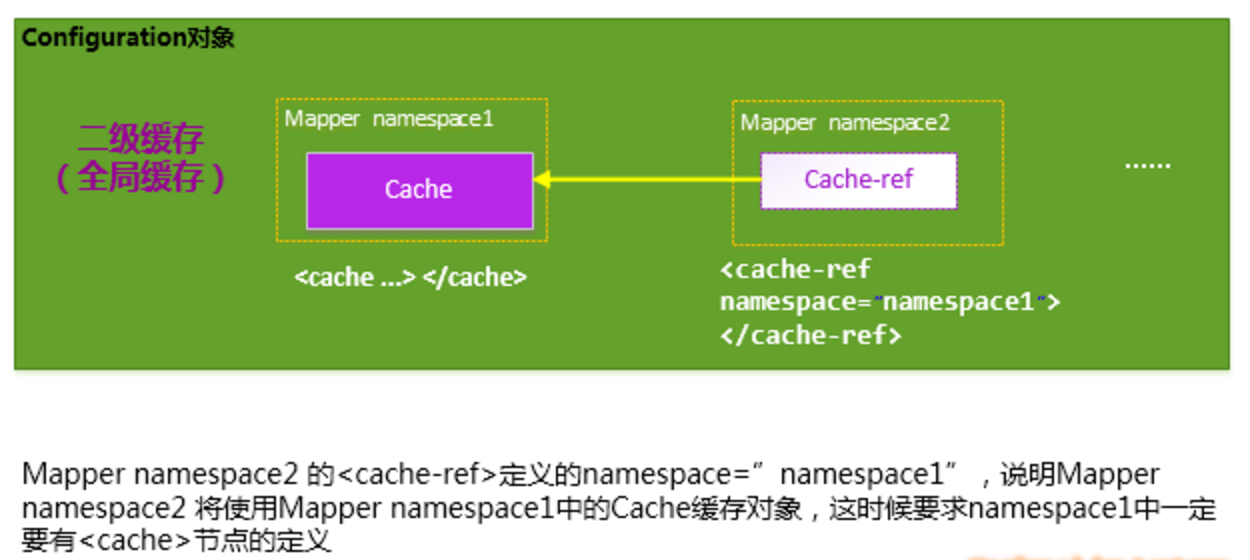
在 Mapper 中配置了 cache 标签之后,这个 Mapper 中的 Select 语句就支持二级缓存了。如果想要单独关闭某条语句的二级缓存,可以使用 useCache 标签,在对应的语句中配置 useCache = false。useCache 默认为 true,所以除非要关闭,否则不用单独配置。
1
| <select id="getStudentById" parameterType="int" resultType="entity.StudentEntity" useCache="false">
|
Mybatis 内部实现了一系列的 Cache 缓存实现类,如下:
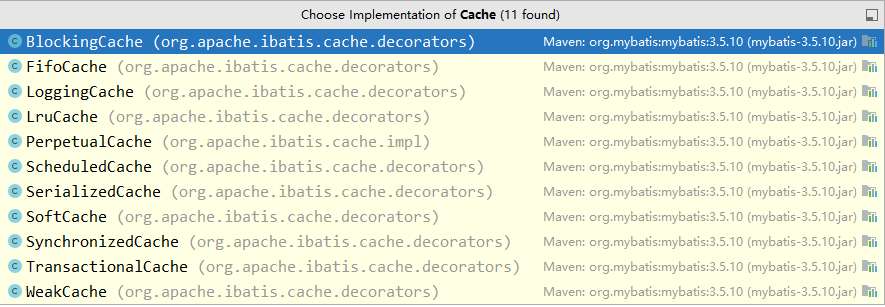
它们各自的能力如下:
SynchronizedCache:同步 Cache,实现比较简单,直接使用 synchronized 修饰方法。LoggingCache:日志功能,装饰类,用于记录缓存的命中率,如果开启了 DEBUG 模式,则会输出命中率日志。SerializedCache:序列化功能,将值序列化后存到缓存中。该功能用于缓存返回一份实例的 Copy,用于保存线程安全。LruCache:采用了 Lru 算法的 Cache 实现,移除最近最少使用的 Key/Value。PerpetualCache: 作为为最基础的缓存类,底层实现比较简单,直接使用了HashMap。
用户在配置二级缓存时,可以手动指定 Cache 的实现类,也可以自定义 Cache 实现类,将 Cache 实现类配置在 <cache type=""> 的 type 属性上即可。
接着来分析一下源码,在看源码的时候带着一个疑问:为什么 select 之后必须执行 sqlSession 的 close() 或 commit() 方法二级缓存才会生效?
直接看 CachingExecutor 的 query() 方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| @Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list);
}
return list;
}
}
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
|
判断是否需要刷新缓存的方法:flushCacheIfRequired(),这个方法只有在 insert/update 时才会调用
1
2
3
4
5
6
| private void flushCacheIfRequired(MappedStatement ms) {
Cache cache = ms.getCache();
if (cache != null && ms.isFlushCacheRequired()) {
tcm.clear(cache);
}
}
|
注意这里的 tcm.clear() 方法,上面 query() 方法中还有 tcm.getObject() 和 tcm.putObject(),这个 tcm 是 TransactionalCacheManager 对象的引用,来看下它的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| public class TransactionalCacheManager {
private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap<>();
public void clear(Cache cache) {
getTransactionalCache(cache).clear();
}
public Object getObject(Cache cache, CacheKey key) {
return getTransactionalCache(cache).getObject(key);
}
public void putObject(Cache cache, CacheKey key, Object value) {
getTransactionalCache(cache).putObject(key, value);
}
public void commit() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.commit();
}
}
public void rollback() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.rollback();
}
}
private TransactionalCache getTransactionalCache(Cache cache) {
return MapUtil.computeIfAbsent(transactionalCaches, cache, TransactionalCache::new);
}
}
|
TransactionalCacheManager 中持有一个 Cache 和用 TransactionalCache 包装后的 Cache 的映射关系,CachingExecutor 默认就使用 TransactionalCache 包装初始生成的 Cache,它的作用是** 如果事务提交,对缓存的操作才会生效,如果事务回滚或者不提交事务,则不对缓存产生影响。**
看一下 TransactionalCache 的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
| @Override
public void clear() {
clearOnCommit = true;
entriesToAddOnCommit.clear();
}
@Override
public Object getObject(Object key) {
Object object = delegate.getObject(key);
if (object == null) {
entriesMissedInCache.add(key);
}
if (clearOnCommit) {
return null;
} else {
return object;
}
}
@Override
public void putObject(Object key, Object object) {
entriesToAddOnCommit.put(key, object);
}
public void commit() {
if (clearOnCommit) {
delegate.clear();
}
flushPendingEntries();
reset();
}
private void flushPendingEntries() {
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
delegate.putObject(entry.getKey(), entry.getValue());
}
for (Object entry : entriesMissedInCache) {
if (!entriesToAddOnCommit.containsKey(entry)) {
delegate.putObject(entry, null);
}
}
}
private void reset() {
clearOnCommit = false;
entriesToAddOnCommit.clear();
entriesMissedInCache.clear();
}
|
回到开头提到的问题:为什么 select 之后必须执行 sqlSession 的 close() 或 commit() 方法二级缓存才会生效?
首先来看一下 sqlSession 中的 close() 和 commit() 方法的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| @Override
public void close() {
try {
executor.close(isCommitOrRollbackRequired(false));
closeCursors();
dirty = false;
} finally {
ErrorContext.instance().reset();
}
}
@Override
public void commit(boolean force) {
try {
executor.commit(isCommitOrRollbackRequired(force));
dirty = false;
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error committing transaction. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
|
开启了二级缓存,会执行 CachingExecutor 的 close() 和 commit() 方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| @Override
public void commit(boolean required) throws SQLException {
delegate.commit(required);
tcm.commit();
}
@Override
public void close(boolean forceRollback) {
try {
if (forceRollback) {
tcm.rollback();
} else {
tcm.commit();
}
} finally {
delegate.close(forceRollback);
}
}
|
可以看到,这两个方法都执行了 tcm.commit(),在 tcm.commit() 中,会执行 flushPendingEntries() 方法,flushPendingEntries() 会 将待提交的数据刷新到缓存中,之后在 query() 时,通过 tcm.getObject() 才能拿到缓存数据。
参考文章
Mybatis详解 - Java全栈知识体系
聊聊MyBatis缓存机制 - 美团技术团队