对于文件乱码的问题一直有种一头雾水的感觉,最近又碰到了这个问题,正好借着这个机会学习一下文件编码相关的知识。
问题描述
网站中包含一个查看文件的功能,目前文件是通过 layer 弹窗的形式来展示,但测试下来部分文件会出现乱码的情况,如下:
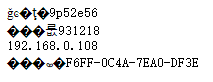
这个问题根本原因是:打开文件时使用的编码,与文件保存时使用的编码,两个编码不一致导致的。
上面测试的几个出问题的文件,编码方式都是 GBK,而浏览器默认使用 UTF-8 编码打开文件,编码和解码规则不同,因此出现了乱码。
这里放上 IM开发基础知识补课(八):史上最通俗,彻底搞懂字符乱码问题的本质 这篇文章中关于乱码的描述:

要解释乱码的问题,首先要理解两个关键概念:字符集 和 字符编码。拿上面的 UTF-8 和 GBK 编码为例,它们使用的字符集和字符编码分别是:
- **
GBK**。字符集:GBK字符集;字符编码:GBK编码。 - **
UTF-8**。字符集:Unicode字符集;字符编码:UTF-8编码。
字符集 中定义了所有可使用的字符,它包含了 字符 和 字符对应的代码点。不同字符集对字符的代码点计算方式是不同的,所以同一个字符在不同 [字符集] 中对应的代码点是不同的。还是拿 UTF-8 和 GBK 为例:
GBK字符集 主要覆盖中文。字符 [你] 在GBK字符集中的代码点是0xC4E3。Unicode字符集 是一个全球字符集,它覆盖所有已知的书写系统,其中GBK字符集中的所有字符它也全部包含。字符 [你] 在Unicode字符集中的代码点是U+4F60
字符编码 是将字符集中的代码点转换为字节序列的一种方式,计算机能够存储和处理这些字符。不同的字符编码可以对同一个字符集进行编码,比如 UTF-8、UTF-16、UTF-32 三种字符编码使用的都是 Unicode 字符集。但三种字符编码不能兼容,如果使用 UTF-8 编码,使用 UTF-16 进行解码,会出现乱码的情况。
关于字符编码更多的知识,这里就不深入了,比如上面的案例中,还可以继续深究:为何只有中文部分乱码了,英文、数字、符号都是能够正常展示的?如果想深入了解建议阅读一下下面几篇文章:
- 字符编码那点事:快速理解ASCII、Unicode、GBK和UTF-8
- 史诗级计算机字符编码知识分享,万字长文,一文即懂!
- IM开发基础知识补课(八):史上最通俗,彻底搞懂字符乱码问题的本质
- Unicode与JavaScript详解
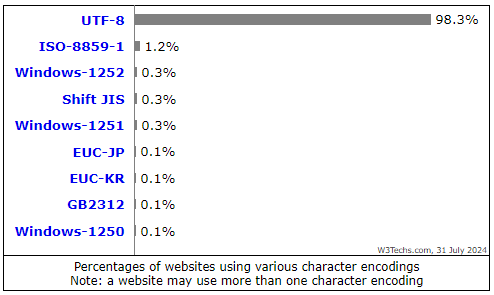
附:在 Usage statistics of character encodings for websites 这个网站统计了目前各种字符编码被使用的比例,如下:
处理思路
经过上面对乱码原因的分析,针对页面文件渲染时的乱码问题,有如下两种处理思路:
- 在渲染文件内容前,想办法确认文件的字符编码。
- 保存文件时,使用统一的编码进行保存,比如统一按照
UTF-8格式保存。
经过调查,服务端和网页端都可以处理,下面将可行的方案列出来。
网页端处理。html 代码中可以通过指定 <meta charset="xxx"> 的形式来指定网页的编码,如果要加载 GBK 编码的文件,那么就指定 charset="GBK" 就可以了。但是在指定 charset 前,需要先确定文件的编码。有如下几种方式可以尝试:
- 通过第三方库检测文件编码,比如 jschardet。
- 请求文件
url返回内容为字节流信息,然后先将文件通过utf-8编码读取出来,判断内容中是否包含乱码字符(�),如果包含再将文件转换为GBK编码。(注:其他编码格式的文件还是会出现乱码的问题) - 文件编码由用户自己判断。在页面中增加一个选择框,供用户选择加载文件时使用的字符编码。默认使用
utf-8加载文件,如果用户发现有乱码的情况,那么自行切换编码格式。 - 请求文件
url返回内容为文本信息(使用默认的编码,也就是UTF-8),之后在JS端将乱码的内容恢复。(尝试过后发现无法这么处理,这个步骤相当于文件先用GBK编码,再用UTF-8解码,之后再用GBK编码,这么一套操作下来整个编码全乱了)在 乱码恢复指北 这篇文章中看到,�这类字符是通过
UTF-8读取GBK编码中文内容时,UTF-8编码将无法显示的字符替换为该符号,对应的码位为0xFFFD,类似的还是 [锟斤拷] 这类字符(用UTF-8读取GBK编码的文件,再用GBK读取),这类字符是无法恢复了。

服务端处理。
- 存储文件时(
txt、doc等文本文件),文件编码统一使用utf-8格式进行存储。(尝试过后发现,在Java中将MultipartFile使用统一字符编码存储时,还是需要知道原文件的编码,否则强行存储会出现乱码情况) - 存储文件时,获取文件的编码格式,将编码格式拼接到
url尾部,之后读取时根据这个编码格式进行加载。注:服务端获取文件编码,可以通过 Apache Tika 库来处理
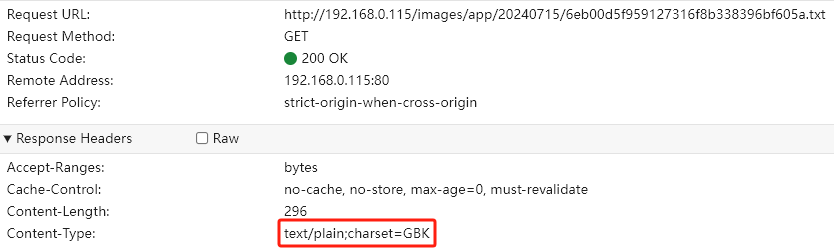
- 访问文件
url目前是请求服务端的rsdun-articles服务,在该服务中增加处理,访问文本类文件时,获取文件的编码格式,并直接指定返回响应中的contentType为对应的编码,如下:
在尝试上面几个方案时,碰到了很多坑。比如文件目前是通过 layer.open() 打开的,这里开启的是一个子 iframe 页面,如果想将在页面头部添加 <meta charset='GBK'> 这个标识,那么只能在页面加载完成后获取子 iframe 的 document 属性,然后将这个 charset 标识插入到页面中,如下:
1 | layer.open({ |
但是这样插入会出现跨域问题,导致 charset 标识无法被插入,如下:

解决了跨域问题,charset 成功插入到页面中了,但是页面中的文件内容仍然是乱码。搜索了一下,原因如下:浏览器在解析 HTML 时会遵循字符集声明,如果未指定,那么默认是 UTF-8。一旦解析开始,字符集设置是固定的。后续尝试通过 JS 修改字符集不会对已经解析的内容产生影响。
解决办法
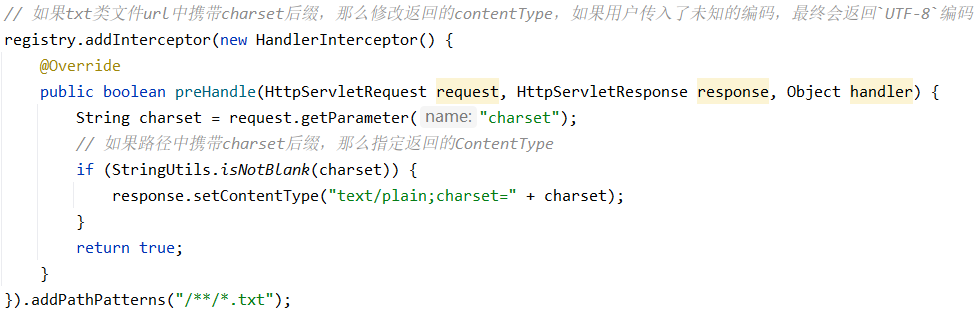
结合上面的几个处理思路,最终选用的方案如下:**服务端拦截携带 charset=xxx 后缀的 url(目前进拦截 txt 文件),这些 URL 请求的返回的 ContentType 会被修改为对应的 charset**,如下:
网页端仍然通过 layer 弹窗的形式展示文件内容,文件字符编码的检测由用户来判断,在弹窗中增加选择框,选择框中提供常用的字符编码,用户可以自行切换,如下:
文件编码选择 [由用户自行判断,而不是由程序自动检测] 的原因,是因为自动检测文件编码的方案并不能100%保证检测结果准确,并且这类方案涉及文件 IO 操作,会影响性能。
注:目前 [即时通讯信息检索] 页面的文件中,只有
txt和txt类文件,因此上面的处理方案目前仅针对txt类文件。
参考文章
字符编码那点事:快速理解ASCII、Unicode、GBK和UTF-8
Detect-File-Encoding-And-Language