本篇尝试对一个包含【依赖子查询】的 SQL 语句进行优化,但是优化后的 SQL 语句反而效率更差了,下面记录一下整个过程。
项目中存在一个接口: GET /circleinfo/list - 商友/好友圈信息拉取,这个接口 sql 语句比较复杂,一直想找机会对其进行优化,sql 语句如下:
1 | <select id="selectListBySortAndInfoNum" resultMap="BaseResultMap"> |
它的执行计划如下:


可以看到其中包含了大量 DEPENDENT SUBQUERY(依赖子查询),这个值是 mysql 执行计划中 select_type 字段的值,这个字段包含了如下几种类型:(来源: chatgpt)
- SIMPLE:没有使用【子查询】或【联合查询】。
- PRIMARY:最外层的查询。
- UNION:UNION 操作中的查询。
- DEPENDENT UNION:依赖于外部查询的 UNION 子查询。子查询的结果取决于外部查询的行
1
2
3
4
5
6
7SELECT name
FROM employees e
WHERE department_id IN (
SELECT department_id
FROM departments d
WHERE d.location = e.location
); - DEPENDENT SUBQUERY:依赖于外部查询的子查询,这种子查询在处理外部查询的每一行时都需要执行
1
2
3
4
5
6
7SELECT name, salary
FROM employees e
WHERE salary > (
SELECT AVG(salary)
FROM employees s
WHERE s.department_id = e.department_id
); - SUBQUERY:独立于外部查询的子查询。
1
2
3
4
5
6
7SELECT name
FROM employees
WHERE department_id IN (
SELECT department_id
FROM departments
WHERE location = 'New York'
); - DERIVED:FROM 子句中的派生子查询,作为临时表进行处理。
1
2
3
4
5
6
7SELECT dept_name, avg_salary
FROM (
SELECT department_id, AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
) AS dept_avg
WHERE avg_salary > 50000; - UNCACHED:UNION 或子查询结果集不缓存的查询。
其中 DEPENDENT SUBQUERY 是一个在 EXPLAIN 输出中表示子查询的类型,表明该子查询的执行依赖于外部查询的当前行。换句话说,子查询的结果取决于外部查询中的某些值,导致子查询在外部查询处理每一行时都被重新执行。而上面的语句出现 DEPENDENT SUBQUERY 是因为 子查询 t_app_circleinfo_look 的查询条件中依赖于外查询 t_app_circle_info 中的 info_uid。
理清了这个概念,来分析下上面 sql 的执行计划:
- 先执行了外部查询,扫描到了 3566 行数据
- 之后执行依赖子查询,第1步中扫描到的每一条数据都需要执行一次子查询,也就是说,每一个依赖子查询都被执行了 3566 次。而子查询进行的是全表查询,每个自查选要扫描 153 行数据。
- 上面执行计划显示,共有 8 个依赖子查询,因此总共需要扫描
3566 * 153 * 8行数据,扫描的数据量直接破了百万…
尽管如此,这行 sql 的查询时间并不是很长,整体耗时在 0.1 秒左右。

可能是因为数据量比较少的原因,为了模拟真实情况,这里将外查询对应的表(t_app_circle_info)的数据进行扩充,模拟增加 100w 条数据:(注:这里为了不影响现有的数据,额外创建了一个数据库进行测试)
1 | public static void main(String[] args) { |
注:原本使用的是存储过程生成 100w 条数据,但是存储过程执行异常缓慢,因此替换为了上面这种方式。
之后再执行一次上面的语句进行测试,耗时基本在 3 秒左右。接下来尝试对这个 sql 进行优化,优化目标是消除语句中的依赖子查询,优化后的 sql 如下:
1 | <select id="selectListBySortAndInfoNum" resultMap="BaseResultMap"> |
原先的依赖子查询改为使用 join 代替,优化后的耗时变成了 4.7 秒左右,耗时反而更长了😅,看下这个 sql 的执行计划:

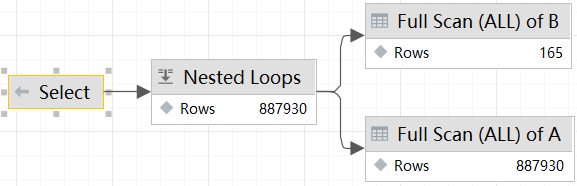
原先的 DEPENDENT SUBQUERY(依赖子查询)变成了现在的 NESTED_LOOPS(嵌套循环联接),嵌套循环联接的工作原理如下:(来源:chatgpt)
- 外部表扫描: 从外部表(通常是查询中的第一个表或子查询的结果)中读取一行数据。
- 内部表扫描: 对于外部表中的每一行,扫描内部表(通常是查询中的第二个表)以找到匹配的行。
- 结果合并: 将外部表和内部表中匹配的行组合成最终的结果集。
外部表的每一行数据仍然需要查询一次内部表,这与上面的依赖子查询好像没有区别,但为何这里的执行时间反而更久了。对两个 sql 进行分析,发现 原始 sql 中的依赖子查询只有在 limit_user != 0 时才会执行,而添加的 100w 条测试数据中,limit_user = 0 占大多数,所以依赖子查询实际执行次数并没有 Explain 执行计划中表现的那么多。而优化后 sql 的嵌套循环联接则是 每一个外部查询数据都会执行,因此反而耗时更长。难道是因为这个?测试一下,对测试的 100w 条数据进行调整:

之后再执行查询,两个 sql 的耗时都有所增加,但优化前的 sql 仍然比优化后的 sql 耗时要短(优化了个寂寞)……
继续看下 NESTED_LOOPS ,对于 NESTED_LOOPS 的优化建议通常有如下几个:
- 小表驱动大表。上面的 sql 是大表驱动小表,这个 sql 不支持优化为小表驱动大表。
- 连接条件匹配索引。上面的连接条件是
A.info_uid = B.info_uid,其中t_app_circle_info表的info_uid是主键,因此可以为t_app_circleinfo_look的info_uid增加索引。 添加了索引之后,查询速度由 4.7 秒提升到了 3.2 秒左右,仍然没有原 sql 耗时短。
添加了索引之后,查询速度由 4.7 秒提升到了 3.2 秒左右,仍然没有原 sql 耗时短。
MySQL 8.0 的优化
上面案例中的 sql 是在 MySQL 5.7 下测试的,在 子查询:放心地使用子查询功能吧! 这篇文章中提到,MySQL 8.0 对子查询进行了优化,在本地配置了 MySQL 8.0.17,将测试的 100w 条数据添加进来,执行了上面最初的 sql,整体耗时在 2 秒左右(提升了 1 秒),对应的执行计划也发生了改变,如下:

可以看到,MySQL 8.0 的执行计划中多了 Filter。这里的 Filter 执行的操作是 根据查询条件进行数据过滤,相当于在全表扫描前先进行一次数据过滤操作,这样可以减少扫描的行数。在 MySQL 8.0 参考手册 中找到了如下说明:
优化器使用物化来实现更高效的子查询处理。物化通过将子查询结果生成为临时表(通常在内存中)来加速查询执行。MySQL 第一次需要子查询结果时,会将结果具体化到一个临时表中。任何后续需要结果的时候,MySQL 都会再次引用临时表。
除了对子查询的优化外,MySQL 8 还进行其他许多方面的优化,之后有时间学习一下,参考:mysql 8 相比 5.7 都修改了什么
总结
本次 sql 优化属于失败案例,优化 SQL 时还是得结合实际情况,网上提到的如果出现 DEPENDENT SUBQUERY 时,就要考虑对 sql 进行优化,但是本次优化后的 sql 反而效率更低了(可能是优化方式有问题)。
参考文档
MySQL连接查询(join)和子查询(subquery)中的效率问题
慢查优化 - 慎用MySQL子查询,尤其是看到DEPENDENT SUBQUERY标记时(注:文章写于2013,仅供参考)